Introduction
At AETHER, we developed ASTRA, an internal air traffic control (ATC) simulation platform. For ASTRA to feel real, spoken communication has to behave like it does in real operations. Controller instructions must follow ICAO phraseology, maintain a stable Singaporean accent, and be delivered at the right pace. Off-the-shelf TTS systems miss these details, so we had to build something aviation-specific.
Modern neural Text-to-Speech (TTS) systems can sound impressively natural, but aviation is a uniquely unforgiving domain. Small deviations in pronunciation, pacing, or stress—perfectly acceptable in conversational speech—can introduce ambiguity or break realism in training environments.
In Singapore, the problem is even harder. Most commercial TTS systems default to American or British English, while Singaporean English differs in rhythm, intonation, and pronunciation. Mispronounced waypoints or unnatural cadence may seem minor, but they quickly break immersion and risk teaching the wrong habits.
What follows is how we built an aviation-specific, Singaporean-accented TTS system for AETHER, optimized for clarity, speed, and operational reliability rather than expressiveness.
Design Constraints and Challenges
General-purpose TTS systems struggle in ATC contexts due to three tightly coupled constraints.
Accent Stability
Most large-scale TTS datasets are dominated by American and British English, leaving Singaporean English under-represented. This often leads to accent drift and unstable prosody, especially in longer instructions. Few-shot adaptation helps, but consistent accent reproduction remains difficult without sufficient local data.
Aviation Phraseology and Terminology
ATC communication relies on structured, domain-specific language: callsigns, waypoints, runway identifiers, flight levels, and ICAO-standard phrasing. These constructs rarely appear in general speech corpora.
Without explicit handling, TTS models tend to guess pronunciations or apply incorrect emphasis—behavior that is unacceptable in aviation.
Data and Evaluation Limitations
There is no large, publicly available dataset of Singaporean-accented ATC speech. Real-world recordings are scarce, access-restricted, or unsuitable for release, making direct supervised training impractical.
Evaluation presents a similar challenge. Standard Mean Opinion Score (MOS) tests are subjective and slow, while acoustic or ASR-based metrics fail to capture aviation-specific correctness and timing. As a result, TTS systems can sound good without being operationally usable.
System Design
ASTRA integrates a domain-adapted TTS module guided by four requirements:
- Accurate pronunciation of aviation terminology
- A stable and recognizable Singaporean accent
- Fast, intelligible delivery
- Robust long-form synthesis
We adapted and evaluated three TTS models:
- XTTS 2.0 — an autoregressive multilingual voice-cloning model with integrated vocoder
- CSM (Conversational Speech Model) — a cross-lingual text-audio Transformer supporting contextual and expressive synthesis
- ORPHEUS-TTS — a large unified codec-based TTS model capable of high-fidelity generation
To meet real-time constraints, ASTRA uses chunk-based synthesis, splitting long instructions into overlapping segments that are generated and streamed sequentially. This reduces latency while helping prevent alignment drift.
Most aviation discipline is applied before synthesis:
- Numbers are normalized into ICAO-compliant spoken forms
- Callsigns are expanded deterministically
- Runway identifiers and flight levels are handled explicitly
Once the text is correct, the model’s job is deliberately simple: say exactly what it’s given, clearly and without embellishment.
Evaluation and Results
Mean Opinion Scores
TTS quality was evaluated using both human raters (aviation personnel familiar with ICAO radiotelephony) and an LLM-based evaluator, which we experimented with as a way to partially automate evaluation. Samples were rated on a 1–5 scale across:
- Clarity
- Pronunciation accuracy
- Prosody
- Naturalness
- Overall quality
A/B Preference Tests
We also ran pairwise A/B tests to see which TTS samples people preferred. Using identical scripts and speaker gender, raters listened to two samples side by side and chose the one they liked better. The comparisons focused on two types of tests:
- Model vs. Model
- Gender vs. Gender (within the same model)
Evaluation Results
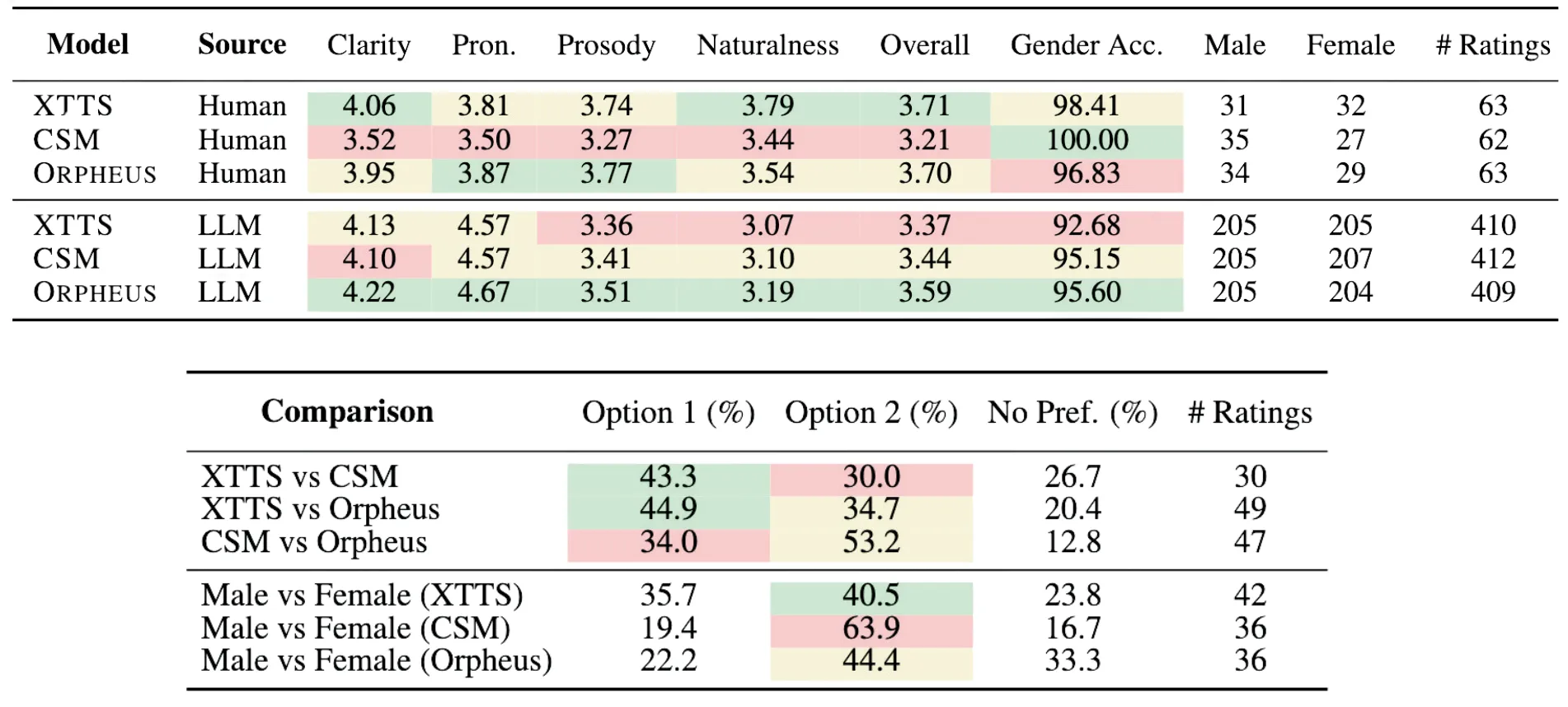
From the tables above (top: MOS results, bottom: A/B testing results), the main takeaways are:
- *TTS 2.0 and ORPHEUS consistently outperform CSM
- XTTS 2.0 is preferred for clarity and ATC intelligibility
- ORPHEUS delivers smoother pacing and more natural prosody
- Female voices are generally preferred across all models
Overall, ORPHEUS provides the most consistent performance, while XTTS 2.0 offers the clearest ATC-style speech.
Limitations and Future Work
Long text inputs occasionally cause hallucinations such as cut-offs or reordered phrases—a known limitation of autoregressive TTS models.
Our next step is more aggressive inference-time chunking and alignment stabilization to further improve long-form reliability.
Conclusion
Realistic ATC speech synthesis is achievable with careful data design, domain-aware preprocessing, and evaluation tailored to aviation. While public datasets remain limited, XTTS 2.0 and ORPHEUS have already shown strong performance, making ASTRA’s Singaporean-accented TTS both clear and operationally reliable.