In both military and civilian contexts, speech remains our primary medium for conveying instructions, information, and (within military settings) commands. For AETHER, the ability to accurately transcribe and understand speech with computers represents a compelling technological target. As we progress along this path, we’ve aimed to capability-drop at each milestone, delivering practical applications while we continue to learn and refine our speech analysis techniques.
Our first target? The humble meeting minutes that administrative necessity that consumes countless person-hours. On top of saving time, an automated system could increase the accuracy by capturing details otherwise forgotten. Not only would this provide immediate value, but it also serves as a perfect testbed for our developing speech technologies.
In the context of meetings, the fundamental information to extract from audio recordings boils down to “who said what.” The what involves Automatic Speech Recognition (ASR) or Speech-to-Text (S2T), a field with extensive research from leading AI labs. For deeper insights into our ASR work, see our companion article on Air Traffic Control ASR which explores the complexities of the what in specialized speech contexts.
Who Said What? The Challenge of Diarization
Here we focus on the who (also known as speaker diarization) and the challenges of applying existing techniques in real-time settings. While algorithms exist for diarization as a post-processing exercise and can achieve impressive results under controlled conditions, real-time application introduces additional complexities. These systems can become even more accurate when provided with a priori information such as the number of speakers or contextual cues about the conversation.
The Speech Processing Challenge
Over the last few months, we’ve learned that computer systems face several fundamental obstacles when attempting to understand human speech.
- Acoustic variability: Speech varies widely based on accent, cadence, tone, and individual speaking styles
- Environmental factors: Background noise, room acoustics, and multiple speakers create signal interference
- Contextual understanding: Language meaning often depends on subtle cues, preceding statements, and shared knowledge
- Conversational flow: Natural speech includes hesitations, false starts, interruptions, and overlapping speakers
To address these challenges, previous-generation speech diarization systems employed complex tailor-made architectures that process audio in multiple stages:

- Voice activity detection (VAD): Isolating segments of audio with speech from larger chunks that mix speech and silence
- Segmentation: Identifying sections where multiple speakers are talking simultaneously
- Speaker identity extraction: Encoding speech segments into high-dimensional latent codes
- Clustering: Grouping these latent codes to assign speaker identities
This fragmented pipeline represents decades of expert-driven system design: essentially a hand-crafted approach that breaks down the problem into discrete components. While effective in controlled settings, these systems often struggle with the messiness of real-world conversations.
Enter ANNoDE: Neural Networks to the Rescue
Instead of trying to achieve gains with more and more components, resulting in a more complicated and fragmented pipeline approach, we’ve followed the research trend toward end-to-end neural networks. While these models effectively “black-box” some of the process, they offer a simpler alternative with superior results!
ANNoDE integrates a state-of-the-art end-to-end neural diarization pipeline from PyAnnote [2, 3]: their approach is particularly elegant - applying a sliding window technique with neural speaker diarization to short, overlapping 5-second chunks of audio. This approach effectively cuts out 2 troublesome components of the pipeline, VAD and segmentation. The local windowed method also makes the problem more tractable and applicable to both looooooong recordings and real-time streamed audio chunks.
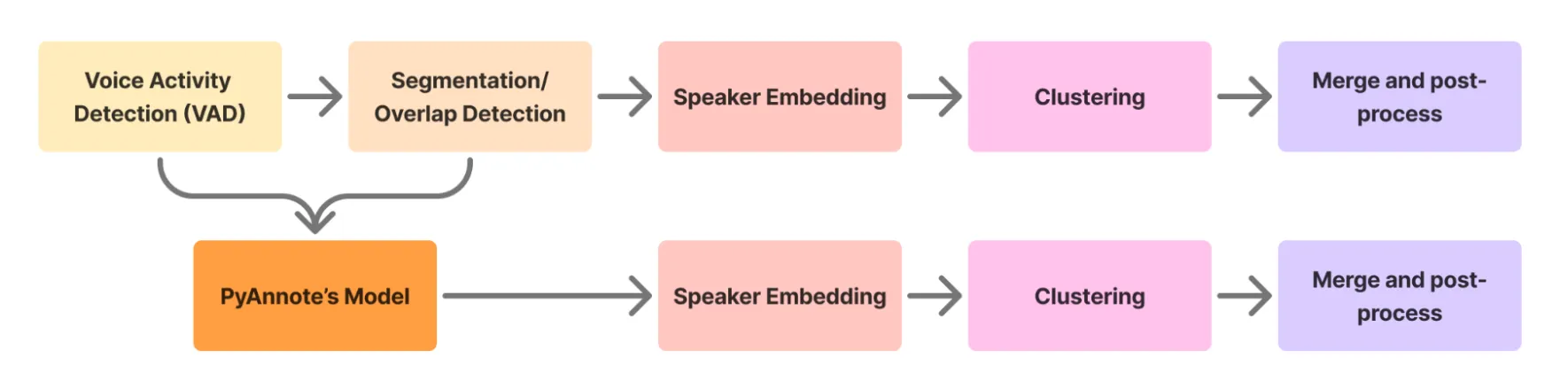
PyAnnote’s method merges the VAD with overlap detection models
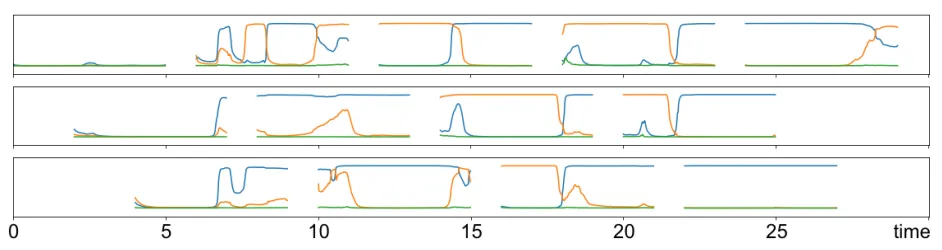
The new PyAnnote model is effectively a local end-to-end diarizer. The other parts of the pipeline stitch these local predictions together to produce a coherent prediction for longer audio clips.
When combined with Whisper’s powerful speech recognition capabilities, ANNoDE delivers a complete solution that can identify speaker changes with significantly higher accuracy than traditional methods, handle overlapping speech more effectively through neural modeling, and generate speaker-attributed transcripts in near real-time.
The early results are promising. On benchmarks, we achieve between 15 to 20% Diarization Error Rate (DER) when using the real-time mode. We’ve also started putting ANNoDE to use in some meetings to save valuable hours in our already packed administrative load. More importantly, though, this has given us a platform to refine our speech understanding capabilities in preparation for more mission-critical applications.
Looking Ahead: Beyond Meeting Minutes
While our initial focus has been on streamlining administrative tasks, the implications of accurate, real-time diarization extend far beyond meeting rooms. In operational environments where multiple speakers communicate critical information, understanding “who said what” can mean the difference between clarity and confusion.
We’re also exploring some fascinating integrations with other emerging technologies. What happens when you combine speaker diarization with emotion detection? Could we eventually detect not just who is speaking and what they’re saying, but also their cognitive state while saying it? The possibilities for operational risk assessment are tantalizing.