In the past few years, it’s felt like the world of search has been on rocket fuel. Advances in artificial intelligence, especially Large Language Models (LLMs) like ChatGPT, Google’s Gemini, Microsoft Copilot, and open-source alternatives such as DeepSeek have completely upended what we expect from information retrieval. No longer are we limited to sifting through pages of keyword hits. Instead, we can ask questions in plain English (or any language) and get back coherent, context-aware answers.
But let’s pause and clear up a few myths before we dive deeper:
Myth: LLMs already “know everything.”
Fact: They’re trained on static data. Without fresh input or online access, they hit a knowledge horizon.
Myth: Closed-source solutions like Copilot or Perplexity have the best accuracy by default.
Fact: Proprietary tools often trade transparency and customization for convenience and may not be able to answer domain-specific questions. Open source tools offer more customizability and can perform comparable to proprietary models if given the right resources.
Myth: LLMs are one size fits all.
Fact: Heavy-duty users such as developers, analysts and knowledge based professionals need deeper, more modular, and more secure access than general-purpose chatbots are able to offer.
The “What Ifs” of LLM-Powered Search
We all know LLMs can compose emails, draft proposals, and even debug simple code. But what if that same model could do more than just guess based on its training? Imagine having the ability to peek into online knowledge bases to pull in the latest standards or research papers, giving you up-to-date and authoritative references instead of relying on stale pre-training data.
Now, layer on the ability to access your internal documentation and code snippets already vetted and approved by your own team. Suddenly, the model isn’t just guessing what might work, it’s tailoring solutions based on your actual systems, your architecture, and your preferences.
And what if it could also take into account policy rules and compliance logic embedded right into its reasoning process? Whether it’s formatting output to align with SOPs or automatically avoiding sensitive disclosures, the model would become not just smart, but trustworthy.
Suddenly, the AI morphs from a chatterbox into a domain-expert sidekick, writing meeting summaries that reference your own slide decks, generating boilerplate reports with footnotes linked to internal guidelines, or even autonomously scaffolding a new microservice based on your existing libraries.
Why Organizations Need Next-Gen IR Systems
Imagine you’re working on a report at 0300 hours for an important meeting, and you know that cost-analysis document is hiding somewhere on your local drive. Was it in the Project Updates folder or tucked under Shared Resources? Every keyword you try in the intranet search comes up empty, and your screen feels like a maze of dead ends.
Now picture an assistant that understands your question in plain language, without needing you to craft the perfect keyword combination. It doesn’t just rely on general internet knowledge, but also taps into both your local repositories and public resources when needed. This assistant is smart enough to filter results automatically based on your job domain, whether you’re an analyst, developer, or operator, ensuring that what you see is not just accurate but relevant.
It doesn’t stop there. Once it gathers the information, it can summarize the content, rank the findings by usefulness, and even format the answer in a way that’s ready for immediate use, be it a report, an email reply, or a set of action points. That’s not science fiction. It’s exactly where modern information retrieval systems need to go, especially in high-stakes environments where security, speed, and accuracy are non-negotiable.
Bringing Home The Black Box
Incorporating AI into enterprise workflows offers lots of potential, yet it also introduces significant risks, particularly when utilizing black box LLMs through external APIs. A survey by Arize AI revealed that the number of Fortune 500 companies citing AI as a risk surged from 9% in 2022 to 56% in recent reports, highlighting growing concerns over AI transparency and accountability.
Data leakage through AI tools is a growing concern for organizations, with recent studies highlighting significant risks associated with the use of generative AI (GenAI) applications. A report by Menlo Security revealed that 55% of GenAI prompts contain sensitive or personally identifiable information (PII), indicating a substantial risk of confidential data exposure.
The issue extends beyond individual prompts. A survey conducted by RiverSafe reported that 20% of organizations experienced data exposure due to employees using AI tools like ChatGPT. The risks are further compounded by the potential for AI models to inadvertently retain and reproduce sensitive information. For instance, in March 2023, OpenAI experienced a data breach where approximately 1.2% of ChatGPT Plus users’ data, including names, chat histories, and payment information, were exposed due to a bug.
AI hallucinations are another big issue, these hallucinations can manifest as fabricated citations, incorrect code, or contradictory statements. For instance, there have been instances where AI-generated legal documents contained fictitious case citations, leading to questions about the reliability of such tools in professional settings.
A study by Stanford University found that AI models hallucinated between 69% to 88% of the time when responding to legal queries. The lack of transparency and explainability in many AI systems further complicates matters. Without clear documentation of how outputs are generated, it’s difficult for organizations to verify the accuracy of AI responses or to understand the decision-making processes of these models. This black-box hinders the ability to ensure compliance with regulatory standards and to maintain accountability within AI-driven operations.
To address these challenges, Retrieval-Augmented Generation (RAG) has emerged as a promising approach. RAG enhances the capabilities of LLMs by integrating them with external data sources, allowing models to retrieve and incorporate relevant information in real-time. This method not only grounds AI outputs in verifiable data but also enables the citation of sources, thereby increasing transparency and trustworthiness.
For example, a comparative analysis by Google Research demonstrated that RAG-based models achieved a 35% reduction in hallucination rates compared to standard LLMs on question-answering tasks.
Thinking Out of The Box
Sure, tools like ChatGPT, Perplexity, and Copilot are great for general queries. But for “hard-core” users:
- Modularity matters. We want to swap out the search component, upgrade the LLM, or plug in a custom classifier without rewriting the whole system.
- Deep search is essential. A simple Google search doesn’t always surface obscure docs buried deep in internal archives.
- Data ownership is important. If you’re not paying for the service, your data often becomes the product.
Earlier last December, our prototype named “web-raider” tested on a curated dataset of military development queries hit 95.94 % recall in our preliminary evaluation, showing that a modular, secured IR layer can outperform one-off integrations. Our work underwent a rigorous triple peer-review process upon submission to ICMCIS 2025, and was recognised for its novelty in military contexts. It has since been accepted for presentation and will be published in IEEE Xplore.
Drawing from the paper, our framework is built like a set of LEGO blocks, each independently replaceable and upgradeable Whether the request calls for a deep dive into public documentation, or a scan across internal code repositories, the controller makes those calls dynamically. It evaluates the query context, understands the user’s intent, and configures the engine lineup accordingly. Think of it as mission control, ensuring that every search runs with the right tools, at the right depth, and in the right place.
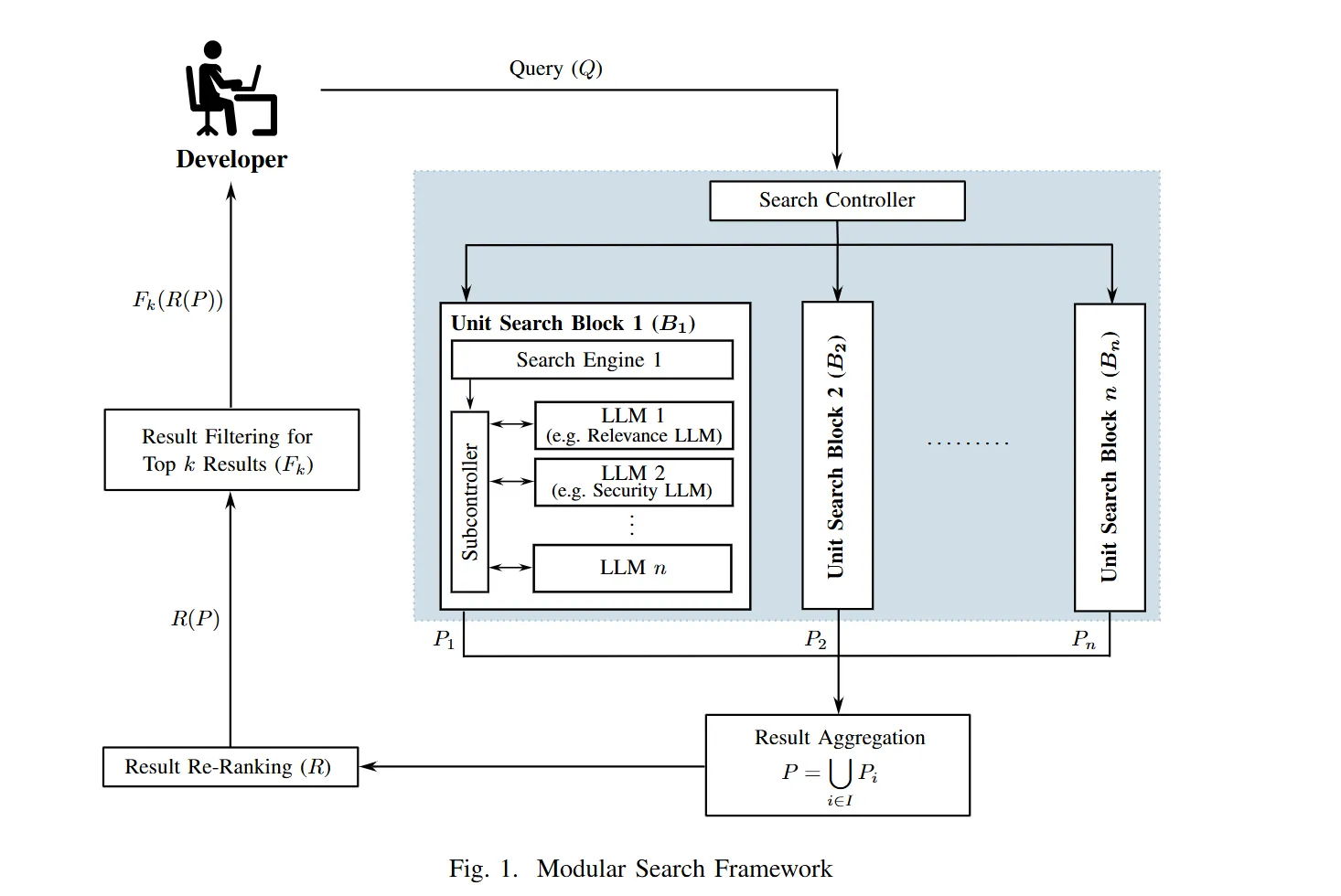
Each unit search block in our framework is designed to connect with a specific type of source and apply refinements tailored to its data domain. The web block reaches out to public resources such as documentation sites, technical forums like Stack Overflow, and scholarly databases including arXiv. It pulls in general-purpose knowledge and the latest public insights, especially useful when internal references fall short.
For example, the local block handles more sensitive territory. This is where it taps into air-gapped repositories and classified folders, carefully navigating internal file structures to fetch documents that are not meant to leave the organization’s four walls. This block is particularly important in environments where data privacy and policy compliance is a must.
Then there’s also the codebase block, which is tuned to fetch peer reviewed code snippets, reusable components, and internal templates. Rather than just scraping code blindly, it focuses on approved code snippets aligned with your architecture and development standards.
Once the data is gathered, the hits from within each of these blocks are passed through a set of LLM-powered submodules. First up is relevance scoring, which isn’t just a one-size-fits-all ranking. It uses your organization’s own metrics to determine what matters most, so the top results are not just technically relevant, but also contextually useful.
Next is clearance filtering, which looks at the document labels and access levels. If something is marked for senior eyes only and you don’t have the badge, you’re not going to see it. This keeps results secure and prevents accidental exposure of sensitive materials.
Once the individual blocks have done their part, the results are brought together. This aggregation step acts like a sorting facility, merging outputs from the web, local, and codebase sources into one coherent list. From there, an LLM-powered rule engine kicks in to re-rank the results not just by raw relevance, but also by factoring in business logic and what’s accurate, appropriate, and useful for your specific context. Finally, you’re presented with the top k results, fine-tuned to suit your needs, access rights, and intent.
Adapting to Open-Source Trends
Since the development of web-raider, the information retrieval landscape has evolved at breakneck
speed, driven largely by innovations in open-source LLM-powered search. Community-driven projects
now routinely match or exceed proprietary offerings in both flexibility and performance.
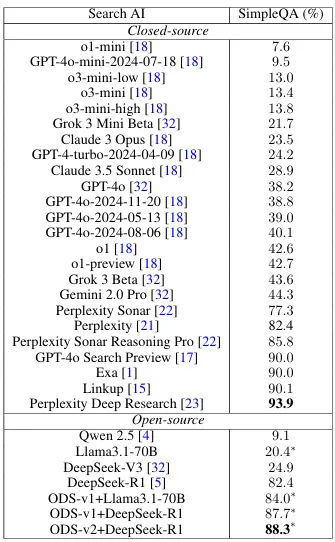
One standout example is Open Deep Search (ODS) introduced in March this year, which achieves near state-of-the-art benchmarks. ODS’s architecture comprises two primary components, the Open Search Tool refines user queries, retrieves information from the web and the Open Reasoning Agent interprets tasks and orchestrates a sequence of actions, including tool calls.
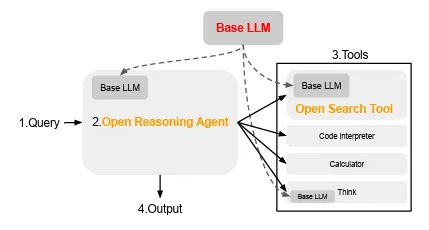
At its core, ODS shares our framework’s commitment to modularity. The Open Search Tool in ODS elegantly handles web retrieval, it takes a user’s natural-language prompt, generates multiple focused query formulations, scrapes the top N results, and segments long pages into context-aware chunks for reranking.
In our adaptation, each of those scraped chunks then passes through our relevance scoring and clearance filtering modules, ensuring that only appropriately classified content moves forward. Meanwhile, the Open Reasoning Agent either operating in a ReAct or CodeAct, coordinates with external tools (including our own local search blocks) to synthesize an answer grounded in both public and private knowledge .
This architectural alignment means we can graft our security-centric components that enforce security protocols and access controls directly onto the ODS pipeline, bringing filters, local-only search, and audit logging into an otherwise public-facing system. Achieving a balance between open-source flexibility and stringent security requirements.
For instance, clearance filters can ensure that users access only information appropriate to their authorization levels, while local-only search blocks can restrict queries to internal repositories, safeguarding sensitive data. Audit trails can provide transparency and accountability, essential for compliance and oversight in military and other high-security contexts. This creates a comprehensive search solution that meets the dual demands of operational efficiency and stringent data protection.
Future Directions
- Multi-Modal Search. Embed diagrams, tables, and even short video snippets in answers think “show me the flowchart and a YouTube tutorial for a creating JS calculator.”
- Behavior-Driven Personalization. Remember user preferences (priorities, favorite programming languages, common query patterns) while still enforcing data-governance guardrails.
- Cross-Language & Region Support. Pull in non-English docs, translate on-the-fly, and return sources from other language regions.
- Full Agentic Pipelines. Technical Requirements → Search Agent → OOAD Agent → Coding Agent → QA Agent → DevOps Agent → Documentation Agent (all iterating together for near-autonomous development lifecycles)
At the point of conceptualising web-raider and its framework paper, alternatives like ODS, or
even the simple Search feature for OpenAI’s ChatGPT UI interfaces were not available, which goes
to show how fast the technology scene, especially AI, moves with or without us.
Web-raider is a testament to AETHER’s spirit of innovation, a willingness to challenge norms and explore new ideas. By blending modularity, security, and LLM-powered reasoning, we believe the next generation of IR systems will not only answer questions faster but do so with the transparency and trust that today’s enterprises and militaries demand.